
简介
CockroachDB是一个支持SQL及完整事务ACID的分布式数据库,CockroachDB结合HLC时钟算法实现了Lock-Free的乐观事务模型,支持Serializable和Snapshot两种隔离级别(注:社区目前在讨论是否去除Snapshot隔离级别,只保留最严格的Serializable隔离级别),默认使用Serializable隔离级别。本文将重点解密CockroachDB如何做到使用NTP时钟同步实现现有的事务模型。
从时间说起
在一个单机系统中,要追溯系统发生的事务先后顺序,可通过为每一个事务分配一个顺序递增的ID(通常称之为事务ID)来标识事务发生的先后顺序。但是对一个分布式系统来说情况就有点特殊。目前分布式系统中常用的事务ID分配方式有两种,一种是由一个中心节点统一产生事务ID;另一种是使用分布式时钟算法产生事务ID。第一种方案实现较为简单,但是存在单点问题,跨地域部署延时较高;第二种方案各个节点可直接获取本地时间不存在单点问题,但是由于各个节点物理时钟无法保证完全一致,事务顺序保证实现较为复杂。
Google Spanner和CockroachDB都采用了去中心化的设计理念,因此使用了第二种方案,但又有所不同。Google使用了一个基于硬件(GPS原子钟)的TrueTime API提供相对比较精准的时钟,具体细节可参考Spanner的论文;而CockroachDB使用了一个软件实现的基于NTP时钟同步的混合逻辑时钟算法(Hybrid Logic Clock)——HLC追踪系统中事务的的hb关系(happen before)。
e hb f 关系 (e happen before f):
1) 如果事件 e 和 f 发生在同一节点,e 发生在 f 之前
2) e 是发送事件,f 是相应的接收事件
3) 基于上述两者的过渡情况
HLC由WallTime和LogicTime两部分组成(WallTime为节点n当前已知的最大的物理时间,通过先判断WallTime,再判断LogicTime确定两个事件的先后顺序),时间获取算法如下所示(其中WallTime用l.j表示,LogicTime用c.j表示,物理时间用pt.j表示):
Initially l.j := 0; c.j := 0Send or local eventl'.j := l.j ; // 备份j节点(也就是当前节点)已知的最大物理时间l.j := max ( l'.j , pt.j );// 和当前物理时间比较取最大值If ( l.j = l'.j ) then c.j := c.j + 1 // 如果物理时间没有改变,就把逻辑时间c加1Else c.j := 0 ; //否则如果物理时间不同,逻辑时间就为0Timestamp with l.j, c.jReceive event of message ml'.j := l.j ; // 备份j节点(也就是当前节点)已知的最大物理时间l.j := max ( l'.j, l.m, pt.j );// 本节点已知最大物理时间、m消息携带的最大物理时间和本机当前物理时间比较,取最大值If ( l.j = l'.j = l.m) then c.j := max(c.j , c.m ) + 1 // 如果三者物理时间相等,本机逻辑时间取本机与m消息携带的逻辑时间较大者加1Elseif ( l.j = l'.j ) then c.j := c.j + 1 // 如果本机已知物理时间最大,那么本机逻辑时间就取本机逻辑时间加1Elseif ( l.j = l'.m) then c.j := c.m + 1// 如果消息携带的物理时间最大,那么本机逻辑时间就取消息携带的逻辑时间加1Else c.j := 0 // 如果当前物理时间最大(注意不是已知),那么逻辑时间可以为0Timestamp with l.j, c.j
在给本地节点产生的事件分配HLC时间时,WallTime部分取当前WallTime和当前物理时间最大值。如果物理时间小于或等于WallTime,LogicTime在原有基础上加一;如果物理时间大于WallTime,LogicTime归零。
节点之间的消息交换都会附带上消息产生时获取的HLC时间,当任一节点收到其他节点发送过来的消息时,取当前节点的WallTime、对端HLC时间的WallTime以及本地物理时间中的最大值。若三者相等,则取当前节点的LogicTime和对端LogicTime最大值加一;若对端WallTime最大,则取对端LogicTime加一;若本地WallTime最大,则取本地LogicTime加一。新的HLC时间更新到本地并作为本地下一个本地事件使用的HLC时间。
简而言之,WallTime表示事件发生时当前节点所能感知到的最大物理时间;LogicTime用来追溯WallTime相等的事件的hb关系。
HLC算法保证了HLC时间有如下特性:
1) 事件e发生在事件f之前,那么事件e的HLC时间一定小于事件f的HLC时间(即:(l.e, c.e) < (l.f, c.f))。
2) WallTime大于等于本地物理时间(l.e ≥ pt.e)。即HLC时间总是不断递增,不会随着物理时间发生回退。
3) 对事件e,l.e是事件e能感知的到的最大物理时间值。也就是说,如果l.e > pt.e,那么一定存在着一个发 生在e之前的事件g,有pt.g=l.e。简单来说是如果出现l.e > pt.e肯定是因为有一个HLC时间更大的的节点把当前节点的HLC时间往后推了。
4) WallTime和物理时钟的偏差是有界的(ε ≥ |pt.e - l.e| )。因为节点之间通过NTP服务校时,那么节点之间的物理时钟偏差一定小于某个值ε。那么对于任一事件b和e,如果b hb e,那么事件b的物理时间pt.b一定满足pt.e + ε ≥ pt.b。结合特性3存在一个事件g满足,l.e = pt.g。那么 pt.e + ε ≥ l.e=pt.g > pt.e。
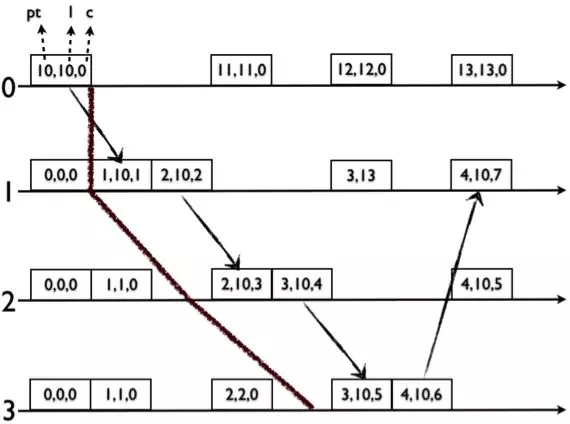
5) HLC支持Snapshot Read。如下图所示,节点0将当前发Snapshot Read的HLC时间hlc.e传播到其他节点,和其他节点产生关联关系(实际上是把其他节点的HLC时间往后推移,使其后续产生的事件的HLC时间大于hlc.e,满足hb关系),这样就能拿到一个确定的全局Snapshot。但是这种Snapshot Read不能保证完全的顺序一致性(linearizability),如下图中的节点3的(2,2,0)事件。
CockroachDB and HLC
CockroachDB在每个事务启动时会在本地获取一个HLC时间hlc.e作为事务启动时间(此行为可理解为HLC理论中的Send or Local Event操作)并携带一个MaxOffset(默认500ms,意思是认为节点之间的物理时间偏差不会超过500ms,该值可在节点启动时根据运行环境的时钟精度调整)。当事务消息发送到其他参与者节点之后更新参与者节点的本地HLC时间(此行为可理解为Receive Event操作),和参与者节点后续启动的事务产生关联关系(hb关联关系)。
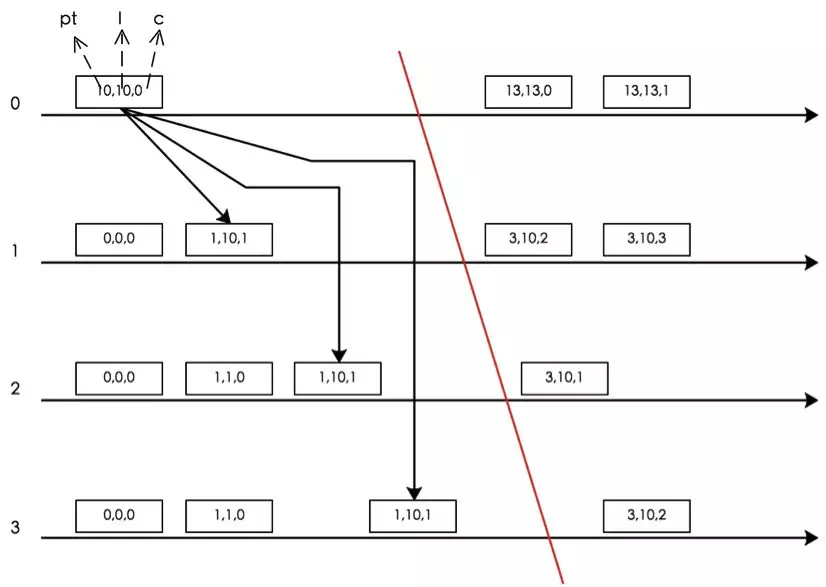
下面我们来看一下CockroachDB如何实现一个Snapshot Read。CockroachDB启动事务e,做了一个假设:认为当前物理时间pt.e+MaxOffset一定是当前系统的最大时间,发生在pt.e+MaxOffset之后的事务的物理时间一定大于当前事务(根据NTP时间同步特性ε ≥ |ptnode1 - ptnode2|得出该假设成立)。根据HLC的特性ε ≥ |pt.e - l.e| ,可得推论:任意时刻当前集群的整体物理时间不可能超过hlc.e+MaxOffset。那么当CockroachDB执行Snapshot Read的时候有:
1) 事务g满足,hlc.e + MaxOffset < hlc.g。根据特性2(对任一事件e,一定有l.e ≥ pt.e),可得出:pt.e < pt.g,e hb g,事务e发生在g之前。
2) 事务g满足,hlc.e < hlc.g <= hlc.e + MaxOffset,那么此时事务e陷入一个叫Uncertain Read的状态,意思是不确定事务g的物理时间pt.g一定大于 pt.e。例如:
-
hlc.e=(10,10,2),hlc.g=(11,11,0),假设MaxOffset=5,此时hlc.g > hlc.e,但是pt.g > pt.e。
-
hlc.e=(10,10,2),hlc.g=(9,11,0),假设MaxOffset=5,此时hlc.g > hlc.e,但是pt.g < pt.e。
在这种情况下CockroachDB无法拿到一个一致的Snapshot,因此当前事务e必须restart,等待时间足够长之后,获取一个新的时间戳 hlc.g +1重新执行。
3) 事务g满足,hlc.g < hlc.e, 那么根据特性5,直接执行Snapshot Read。
如何选择Maxoffset
HLC的正确性很大程度上依赖于NTP服务的授时精度。当NTP服务变得不可靠时,HLC也做一定程度上的容忍,消除NTP服务不可用带来的影响。HLC算法不修改本地物理时间,本地物理时间通过主板上的晶振仍然能在一定时间内保证授时精度不会出现太大的偏差,能保证有足够时间恢复NTP服务。其次任一节点收到一个消息(事务)携带的HLC时间和当前节点的偏差超过Maxoffset,该节点可拒绝此消息(事务)防止该异常的HLC时间扩散。CockroachDB节点同时会定期搜集各个节点的HLC时间,如果当前节点和一半以上节点时间偏差超过Maxoffset,当前节点拒绝外部请求并下线。简而言之,MaxOffset只是在限制节点时间偏差,在超过这个偏差时对相应节点做出相应的处理。
CockroachDB要求Maxoffset ≥ 物理时钟偏差(即NTP时间同步精度偏差)。NTP服务偏差精度可通过如下命令查看:
ntpq -p

offset列代表当前节点物理时间和NTP时间源时间偏差(单位毫秒)。可通过观察一段时间之后offset字段跳变范围决定CockroachDB集群Maxoffset取值范围。一般情况下同机房局域网或者同城机房之间的时钟偏差不会超过200ms,CockroachDB为了容忍网络环境较为恶劣的情况,默认设置成500ms。
总结
CockroachDB使用HLC追踪事务之间的hb关系,使其能用一个确定的HLC时间获取一个一致的Snapshot来实现事务模型。CockroachDB也可以使用和Spanner同样的Commit-Wait机制来实现事务的Linearizability,但是由于NTP服务的精度问题,这个特性不建议开启。
后续我们将进一步剖析CockroachDB事务执行流程、事务隔离级别以及事务并发控制。